Overview of AI
2026-05-07
About AI from start to current
Artificial Intelligence (AI)
Artificial Intelligence is the overarching field of computer science dedicated to creating systems capable of performing tasks that traditionally require human intelligence. Historically rooted in symbolic logic and "if-then" rule-based systems, modern AI has shifted toward a connectionist paradigm. It seeks to simulate cognitive functions such as reasoning, problem-solving, and perception. In academic terms, AI is often defined as the study of intelligent agents: any device that perceives its environment and takes actions that maximize its chance of successfully achieving its goals. Today, AI is no longer a futuristic concept but a foundational layer of modern infrastructure, driving everything from recommendation engines to autonomous systems.
Machine Learning (ML)
Machine Learning is a subset of AI. It learns from the data (using loss functions) to maximize the performance (measured by metrics). Or in simple term, we design a mathematic function to tell ML models that it should make this function as low/high as possible when producing output based on provided data. ML is mostly a bunch of math and statistic so it can be explained using, again, math and statistic. And its explainability is also why ML models are still widely used in domains where the decision can be traced and explained such as financial, healthcare and vice versa. ML comprises multiple types of learning: Supervised learning, Unsupervised learning, Semi-supervised learning, Deep learning, Reinforcement learning, etc. Yes, ML is a superset of Deep learning and Reinforcement learning, which we will see in the next sections.
Some popular models in ML are Linear Regression, Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Principal Component Analysis (PCA), Decision Tree, Random Forest, and a lot more. Courses in Machine Learning are abundant. But for me, I recommend the book "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" or "Machine Learning Cơ bản" (for Vietnamese).
Deep Learning
Deep Learning is a subset of ML. It consists of multiple domains that you can easily see its application around you. All models in this subset are neural networks, which mimicks the human brain. Deep Learning models can learn complex, non-linear patterns in data by utilizing activation functions between layers. According to Universal Approximation Theorems (UATs), a feedforward neural network with at least one hidden layer can approximate any continuous function on a compact domain to any desired degree of accuracy, given a suitable activation function. Additional fact is that this is just one of many approximation theorem: "Taylor series allow to approximate smooth functions by polynomials. Fourier series allow to approximate continuous functions by sums of trigonometric functions" according to this lecutre from Harvard.
You can learn Deep Learning from Deep Learning Specialization course: https://learn.deeplearning.ai/specializations/deep-learning/information
Computer Vision
Computer Vision (CV) is the field that enables machines to "see" and interpret visual information from the world. While humans perceive images effortlessly, a computer sees a grid of numbers (or "pixels"). CV uses architectures like Convolutional Neural Networks (CNNs) and, more recently, Vision Transformers (ViT) to extract features. Its applications are wide range from facial recognition on your smartphone and medical image analysis (detecting tumors) to the complex backbone of self-driving cars, enabling perception and discrimination between a pedestrian and a lamppost in real-time.
Some well-known architecture for CV tasks are AlexNet, ResNet, MobileNet and Vision Transformer. AlexNet, developed by Alex Krizhevsky et al., is one of the most important model for image classification taske, introducing simple but high perform architecture utilizing Convolutional layers. But as networks grew deeper, they became harder to train due to the "vanishing gradient" problem. ResNet solved this by introducing residual connections (or "skip connections"), which is a simple addition operator. For efficiency, MobileNet is designed specifically for mobile and embedded vision applications, it uses depth-wise separable convolutions to stay lightweight and fast without sacrificing too much accuracy. Recently, the scheme shifted to Vision Transformer (ViT), which cuts image into patches and feed to a Transformer for processing.
CV course from Stanford: https://cs231n.stanford.edu/. The course introduce simple task image classification and then build up to CNN and ViT. It also covers Object Detection, Image Segmentation, Video Understanding, 3D Vision, VLM and Robot learning.
Natural Language Processing
Natural Language Processing (NLP) is a branch of artificial intelligence concerned with giving computers the ability to understand, interpret, and generate text and spoken words in pretty much the same way that human can. If Computer Vision is the "eyes" of AI, NLP is the "ears" and "mouth." Applications range from everyday tools like spell-checkers, email spam filters, and translation services to highly sophisticated virtual assistants and chatbots.
Historically, NLP relied heavily on Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), which processed words sequentially. However, the field experienced a monumental paradigm shift in 2017 with the introduction of the Transformer architecture. Transformers use a mechanism called "self-attention," allowing the model to look at an entire sentence at once and understand the context of a word based on its surrounding words. This breakthrough paved the way for massive language models like BERT and the GPT series, which excel at drafting essays, summarizing long documents, writing code, and holding human-like conversations. Current models such as ChatGPT, Gemini, DeepSeek, Grok, etc. all use some variants of attention mechanism.
NLP course from Stanford: https://web.stanford.edu/class/cs224n/. This is recommended and should learn if you want to go deep into NLP
Reinforcement Learning
While other deep learning domains often rely on massive datasets of pre-labeled examples, Reinforcement Learning (RL) takes a completely different approach: learning by trial and error. In RL, an AI "agent" is placed in an environment and must learn to make a sequence of decisions to achieve a goal. It does this through a system of rewards and penalties When the agent takes an action that brings it closer to its goal, it receives a positive reward; if it makes a mistake, it receives a negative reward. Over time, the model learns a "policy" that maximizes its cumulative reward. RL is the technology behind some of AI's most famous triumphs, such as DeepMind's AlphaGo defeating human world champions at the complex board game Go. Today, RL is heavily used in robotics, optimizing logistics, autonomous navigation, and notably, in Reinforcement Learning from Human Feedback (RLHF), which is used to align modern large language models to be safe, helpful, and polite.
You can learn from this course from Stanford: https://web.stanford.edu/class/cs234/
Other term
The rapid evolution of AI has lead to new categories that define the current best or most advanced models.
Generative AI vs AI
Generative AI is a category for model that can "generate" a or some modalities such as text, image, video and sound. ChatGPT, Midjourney, Nano Banana Pro, Claude are generative models. There has been raising concerns in ethical use of generative AI such as generating fake news using ChatGPT or generating "harmful content" videos using Veo3. Personally, I am against these bad uses of generative AI, but I also want to pinpoint that it is "generative AI", not just "AI". The term "AI" includes Machine Learning models or other AI researchs that trying their best to solve real world problems such as drug discovery, robotic surgery, financial risk management, real-time threat detection, etc. and it is not fair to go against these beneficial use of AI. It's "generative AI" not "AI".
Foundation models
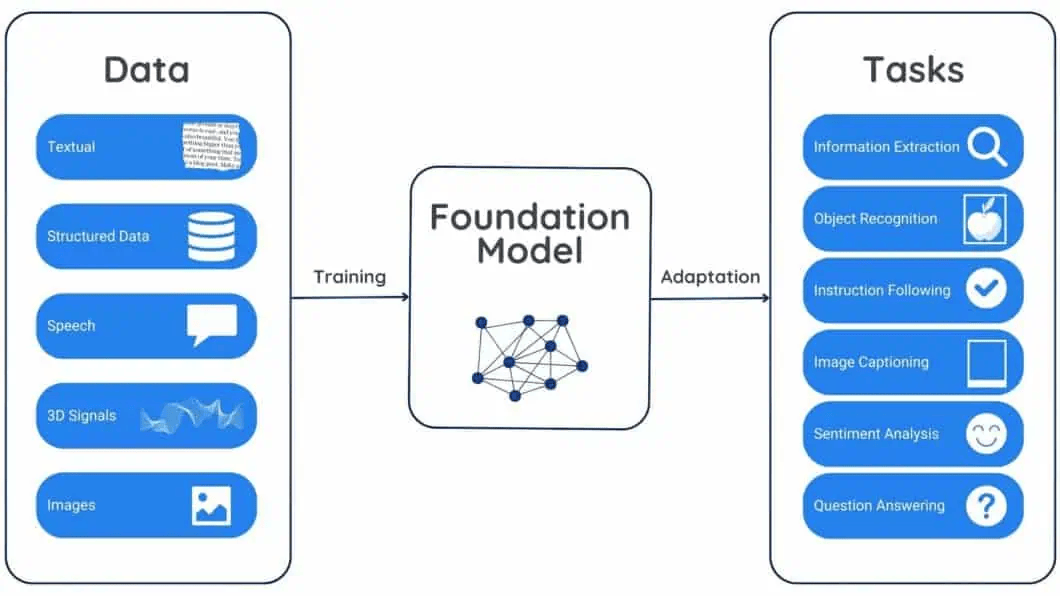
Coined by researchers at the Stanford Institute for Human-Centered Artificial Intelligence (HAI), a "Foundation Model" refers to any model that is trained on a vast quantity of unlabeled data at scale (usually through self-supervised learning) and can be adapted to a wide range of downstream tasks.
In the past, engineers had to build one specific model to translate French to English, and an entirely different model to summarize a medical document. Foundation models flip this paradigm. By understanding the underlying structure of language, code, or images at a foundational level, a single massive model (like GPT-4, Claude, or Llama) can be fine-tuned or simply prompted to perform hundreds of different tasks right out of the box.
Frontier models
"Frontier models" are the bleeding-edge of foundation models. Organizations like the Frontier Model Forum define them as highly capable, large-scale machine learning models that exceed the capabilities currently present in the most advanced existing models.
Because they are pushing the boundaries of what artificial intelligence can achieve, frontier models possess capabilities that are not always fully understood even by their creators until after they are trained. The term is often used in the context of AI safety and policy, highlighting the need for rigorous testing, red-teaming, and alignment to ensure that these immensely powerful, state-of-the-art systems do not pose severe risks to public safety or security before they are deployed to the public.
World models
A World Model is a fascinating and highly theoretical area of current AI research. Instead of simply predicting the next word in a sentence or identifying a dog in a photo, a world model aims to build an internal representation of how the physical world actually works. It understands intuitively that if a glass falls off a table, it will shatter, or if a car turns its wheels, its trajectory will change.
By predicting the future states of an environment based on current actions and physical laws, world models allow AI agents to "hallucinate" or simulate potential futures. This means an AI could test out thousands of scenarios in its own "imagination" before taking a physical action in the real world. Prominent researchers argue that developing robust world models is the crucial next step toward achieving Artificial General Intelligence (AGI), as it bridges the gap between pattern recognition and true spatial and temporal reasoning.
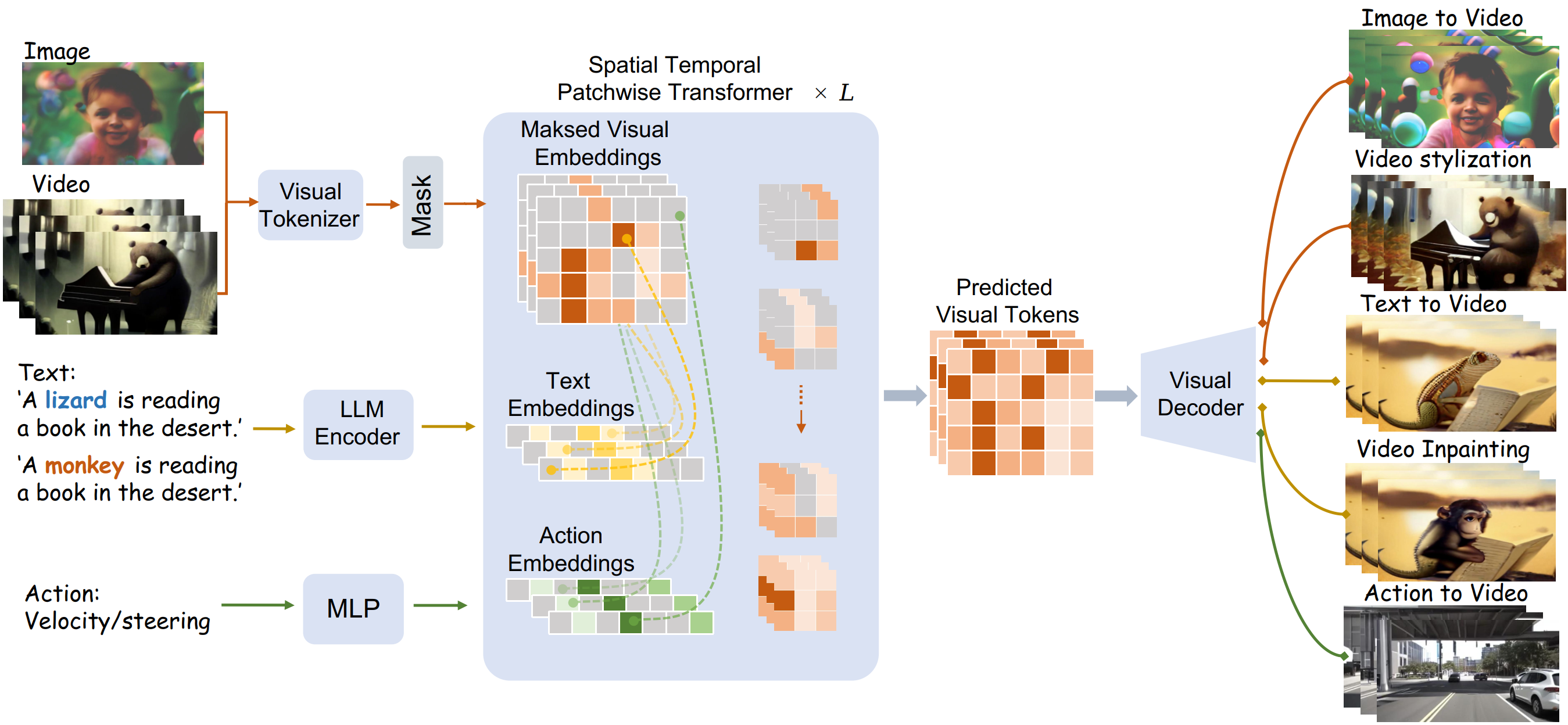
An example world model is WorldDreamer. It is an image generation by predicting masked tokens and is able to generate video from image, text or action. WorldDreamer is also capable of do tasks like image inpainting or stylization. This shows that it can learns different representions and "understand" (kind of) them.