Vesuvius Surface Detection
2026-03-01
Finetune segmentation models on 3D image data
Introduction
Vesuvius Challenge is a competition that introduces a series of problems related to machine learning, computer vision and geometry. The competition is built to encourage community to develop solution used to come up with high performance solution in the recovery of ancient scrolls retrieved from the Vesuvius volcano.
Currently, the Vesuvius Challenge host team is solving 2 problems: Ink detection and Surface Detection for representation.
Datasets
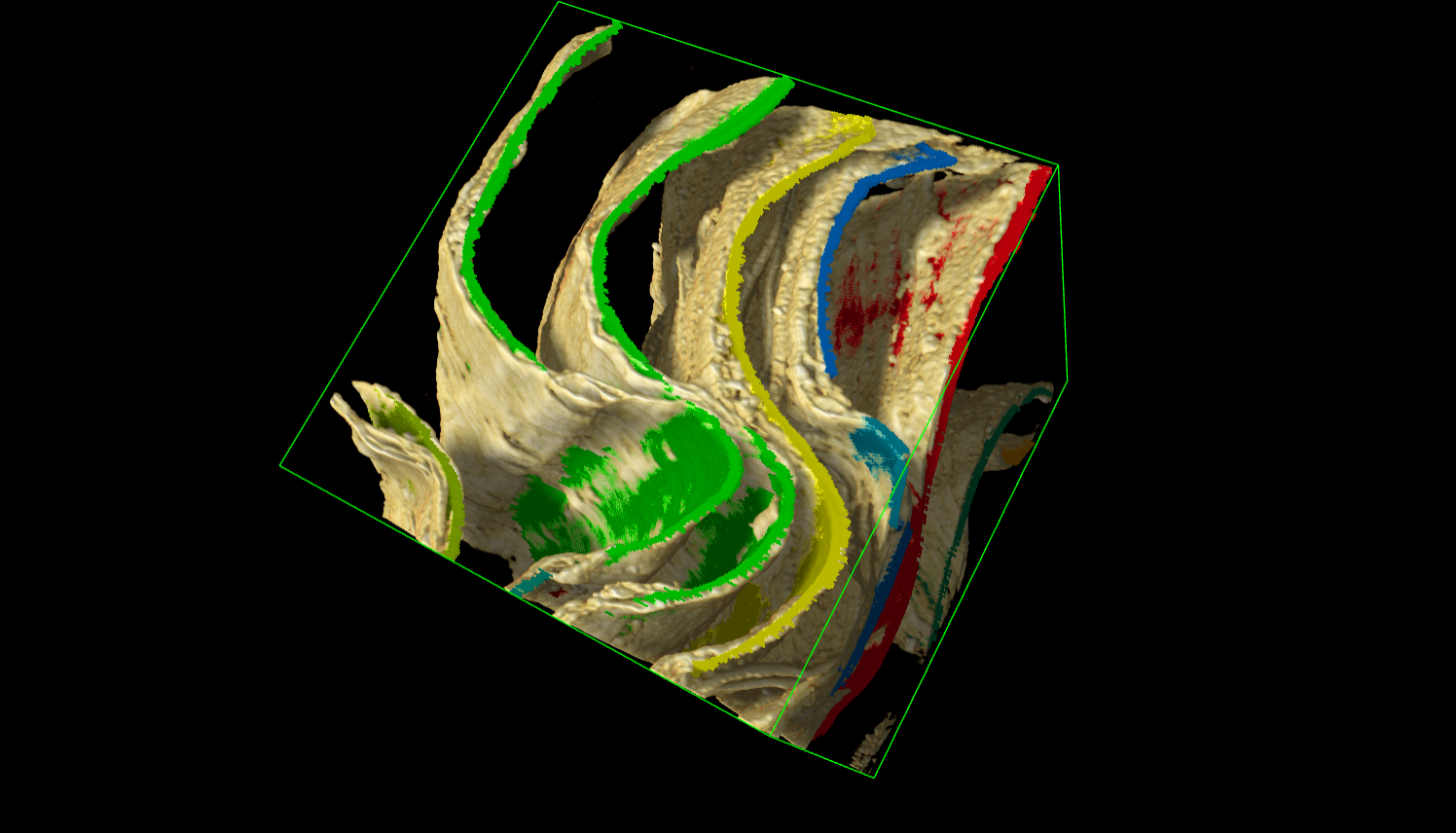
This image shows a sample 3D volume with segmentation mask from my best model. The yellow curve are the scrolls' curve and the colorful line inside the curve is the segmentation mask need to be predicted.
Folder structure:
- train_images/: contains 3D CT scan images of some parts of the scroll
- 1004283650.tif
- ...
- train_labels/:
- 1004283650.tif
- ...
- test_images/: containing public and private test images
- 1407735.tif (only public test is available; private test is available when submitting a notebook)
- train.csv: containing scroll_id and train images' id to map from CT scan image to real scroll
- test.csv: same as train.csv but for test images
My approaches and trials
2.5D UNet approach
The intuitive is easy to understand: because a 3D image can be intepreted as multiple 2D images, we can use 2D model to predict each slice (or patch) of 3D image and then aggregates the output masks into a 3D mask. However, the 2D images here can have more than 1 patch, resulting in shape where . This is due to the fact that in 3D data, ignoring interaction/correlation between depth channels can results in low performance. We can think about RGB images as an example: these are 3D images and we can easily set the channel in Conv2D() to 3 and perform 2D segmentation on each channel Red, Green, Blue and aggregates by averaging or other methods to get the final mask. The same also apply for those 2D images sliced from 3D images (or 3D CT scan to be specific), we slice it from to where and , and set the channel in Conv2D() to D' and perform segmentation.
However, this is sometimes not enough. Like I said about interaction in depth channels, normal aggregation methods may not be effective. The results maks will have artifacts such as horizontal or vertical lines at the edge of each patches, resulting in poor qualitative and quantitative results. In order to avoid this, we have to perform segmentation on overlap patches and then either averaging or Gaussian weighted on the overlapped regions.

Therefore, we can use any 2D segmentation models (e.g. UNet, UNet++, Swin UNETR) to apply in this approach. These models can be obtained from MONAI library. In my approach, I reused some implmentation of UNet with attention mechanism shared by other participants. For loss function in 2D segmentation, I tried ensembled of Dice, Cross entropy, FBeta () and Tversky loss (). I gave up on this approach rather soon to train nnUNetv2 in the next section so the result image above can be a bit messy.
nnUNetv2 approach
A well known framework for segmentation is nnU-Net, which facilitates and standardizes most of the pipeline from preprocessing to training and inference of 2D/3D biomedical image segmentation task.
nnU-Net is developed and maintained by the Applied Computer Vision Lab (ACVL) of Helmholtz Imaging and the Division of Medical Image Computing at the
German Cancer Research Center (DKFZ).
The idea behind the framework is addressed in the official paper such as existing researchs often couple the claimed innovation with confounding performance boosters or lack of well-configured and standardized baselines.
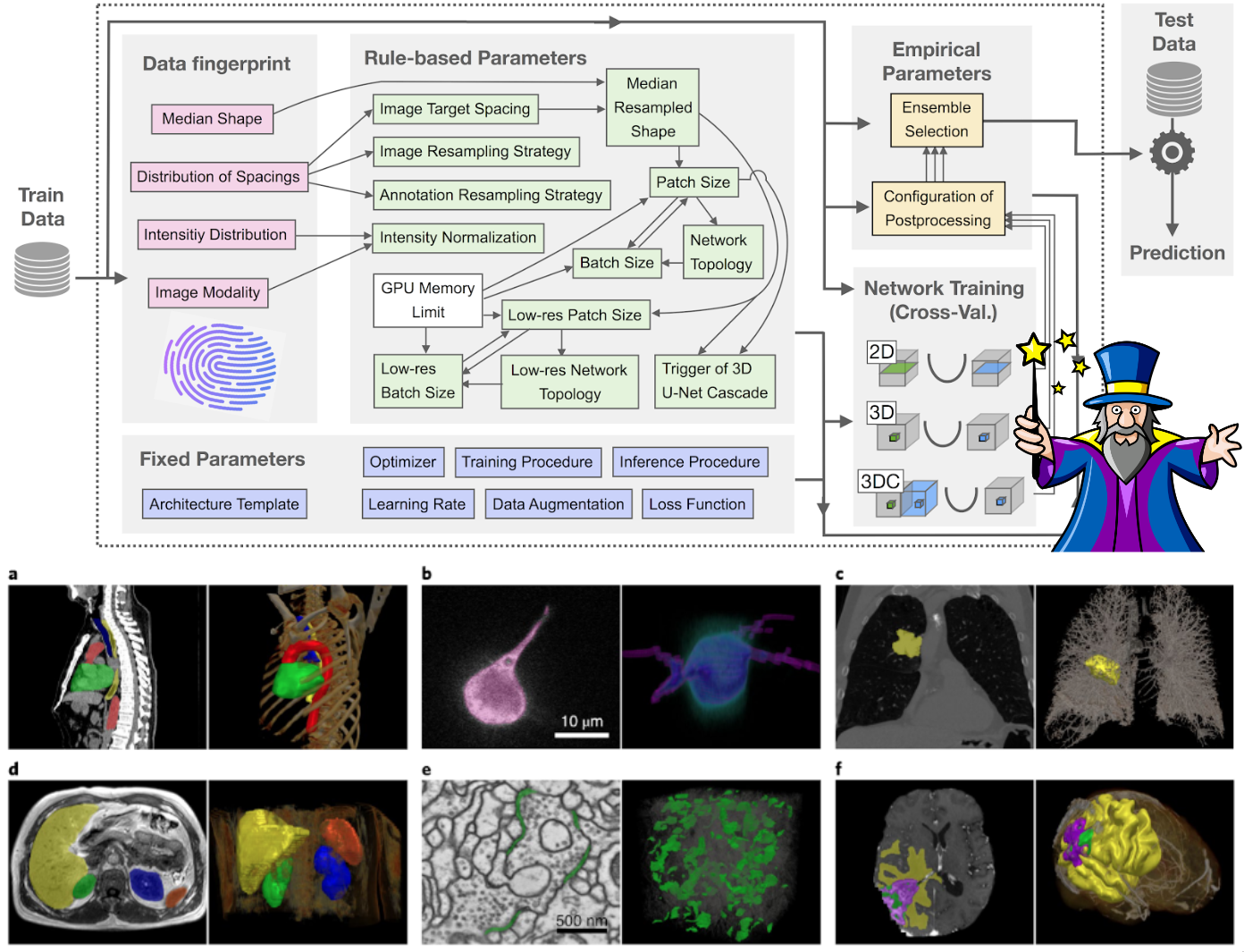
The framework provides a simple CLI so that even someone who is not a programmer can easily have train high performance segmentation models for biomedical applications. For example, a simple pipeline consisting preprocess data, training, hyperparameters tuning, prediction and postprocessing can be easily run with minimal changes as follow:
# Preprocess
nnUNetv2_plan_and_preprocess -d DATASET_ID --verify_dataset_integrity
# Train
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD [additional options, see -h]
# Using npz file to determine the postprocessing that should be used
nnUNetv2_find_best_configuration DATASET_NAME_OR_ID -c CONFIGURATIONS
# Predict (with --save_probabilities, we can use for ensembling)
nnUNetv2_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -d DATASET_NAME_OR_ID -c CONFIGURATION --save_probabilities
# nnUNetv2_ensemble -i FOLDER1 FOLDER2 ... -o OUTPUT_FOLDER -np NUM_PROCESSES
# Postprocess based on nnUNetv2_find_best_configuration above
nnUNetv2_apply_postprocessing -i FOLDER_WITH_PREDICTIONS -o OUTPUT_FOLDER --pp_pkl_file POSTPROCESSING_FILE -plans_json PLANS_FILE -dataset_json DATASET_JSON_FILE
A simple pipeline in nnUNetv2 can be interpreted as follow:
- Reorganize data into format defined in this documentation. This is based on the Medical Segmentation Decathlon (MSD) format.
- Preprocessing using
nnUNetv2_plan_and_preprocessto create a plan. - Train using
nnUNetv2_train. Default epoch is set to 1000, which is a sweet point for performance and requires 52 hours of DDP training on 2xT4 GPU in Kaggle. - Inference using
nnUNetv2_predict - Postprocess using
nnUNetv2_apply_postprocessingor self-defined methods
In detail, most of the hyperparameters for training and inference (e.g. Patch size, Batch size, Depth, Normalization method, Data augmentation and LR Scheduler) are managed by nnUNetv2. Patch size, batch size are chosen based on GPU VRAM. We only need to set the configuration, planner and number of epochs to train.
There are many terms that we need to understand in this framework: configuration, planner and preset.
Planners are the most important component in nnUnetv2. A planner can contains information about plan's name (plans_name), dataset, signature of dataset (spacing, shape,...), type of image reader (image_reader_writer), configurations and planner used.
There are 3 main planner nnUNetPlanner, nnUNetPlannerResEncM and nnUNetPlannerResEncL.
Next, configurations are also the core components. Configurations consist information about image size, spacing, training hyperparamters and model's architecture.
There are 4 main configs 2d, 3d_lowres, 3d_fullres and 3d_cascade_fullres, corresponding to 2D UNet, 3D UNet with low resolution patch, 3D UNet with higher patch size and 3D UNet with 2 stages training (stage 1: train on downsampled images and upsample result to original resolution, stage 2: refine using a second 3D UNet).
Presets are planners with some more settings such as VRAM targets and removal of 5% batch size cap.
More about presets in this documentation.
About my configuration, I use 3d_lowres due to limited GPU VRAM and nnUNetPlannerResEncM planner. Dataset is processed by nnUNetv2. I trained for 1000 epochs in 52 hours on 2xT4 GPU with DDP on a single fold. Full code without postprocess is available at this notebook
Some trials
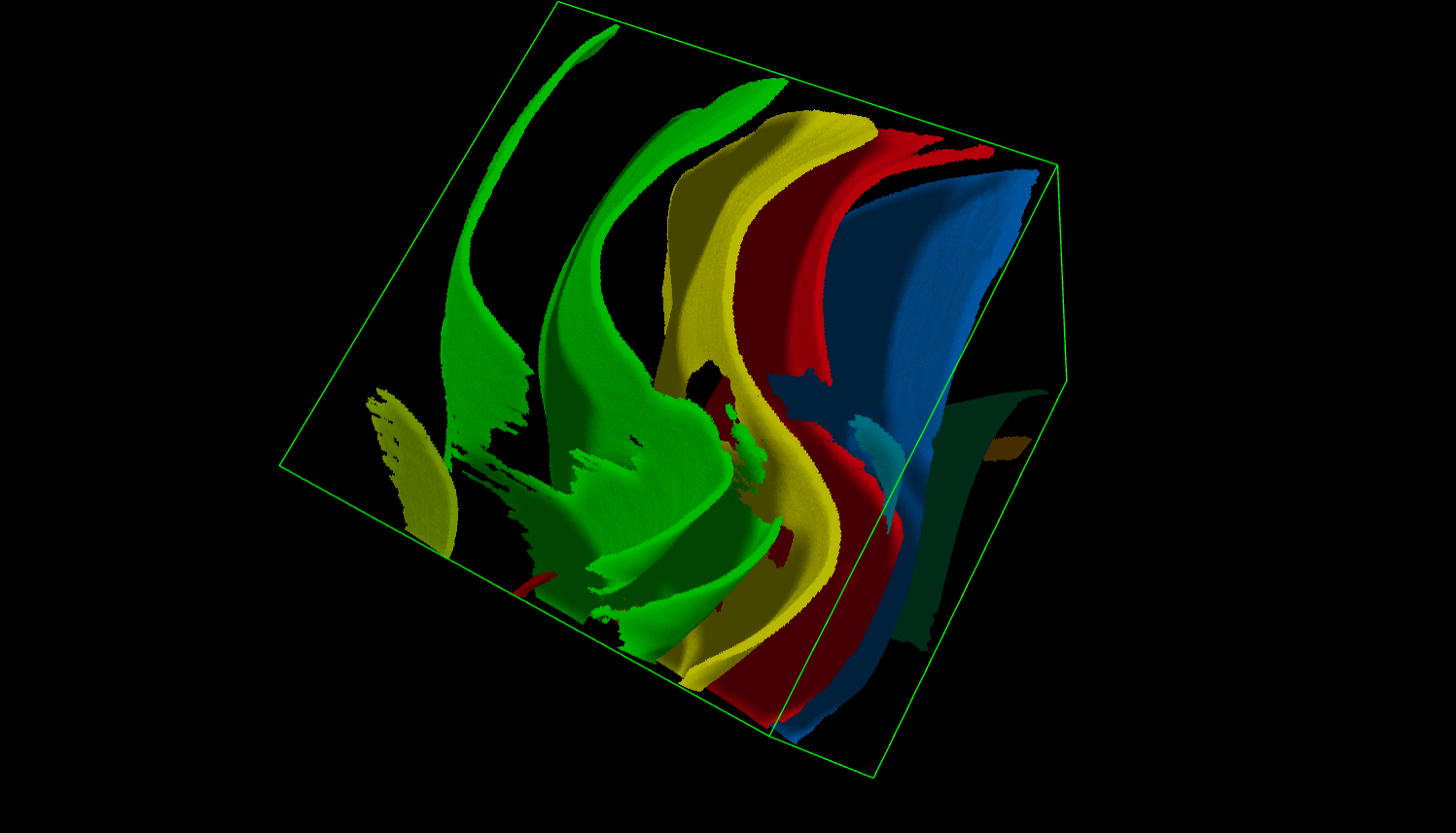
Postprocess with small blobs removal.
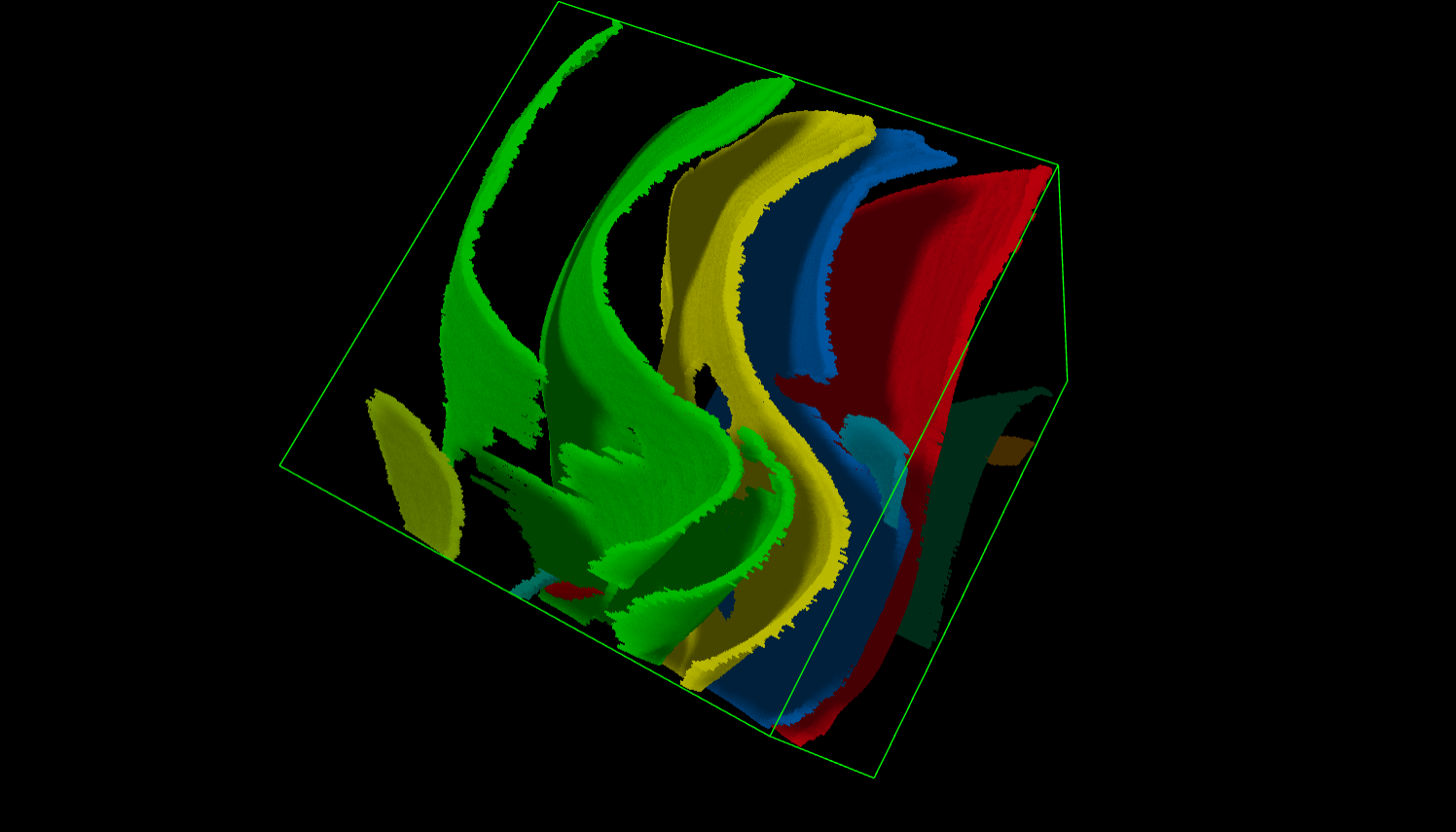
Postprocess with small blobs removal and hole stitching UNet (Gaussian weighting Sliding window). UNet is trained using train images with random hole append to the ground truth curve and loss function is Reconstruction loss L1 and simple heuristic Gradient Loss to improve smoothness. As shown in the image below, the green curve has been filled and exhibits smaller holes than in the previous postprocess image abvove. Despite the fact that this approach is not capable of actually stitching all holes on the curves, it improve the final score to and on public and private test when compared to without postprocessing submission. Full code with postprocess is available at this notebook.
Credit
Images are captured using https://paul-g2.github.io/ScrollSlabViewer/ (repo's owner is also the 1st place winner)