Bridging the Training-Deployment Gap: Gated Encoding and Multi-Scale Refinement for Efficient Quantization-Aware Image Enhancement
CVPRW 2026
Abstract
We present a quantization-aware image enhancement pipeline that preserves quality after deployment by training the model to handle quantization noise directly. The method combines gated encoding, multi-scale refinement, and fake quantization during training to support mobile-friendly inference with strong visual fidelity.
Deep learning models can enhance low-quality mobile photos into those with higher fidelity. But what happens when we compress these heavy models into 8-bit formats to actually run on mobile phones, and the model suddenly turn into a "noise injection machine" instead?
We can trains a Deep Image Signal Processing (Deep ISP) model to map noisy photos from an iPhone 3GS to the clean clarity of a Canon 70D DSLR. In that full-precision floating-point environment, the images look fantastic. Then the model is compressed to 8-bit integers to run on a Snapdragon smartphone processor. The visual output immediately degrades.
The activation distributions inside Deep ISP models are long-tailed and asymmetric. Outlier values directly control color and luminance. When standard Post-Training Quantization (PTQ) crushes those values into a rigid INT8 space, the math shears. Skies turn pink. Textures warp. We resolve this by implementing Quantization-Aware Training (QAT), bringing the constraints of edge deployment directly into the optimization phase.
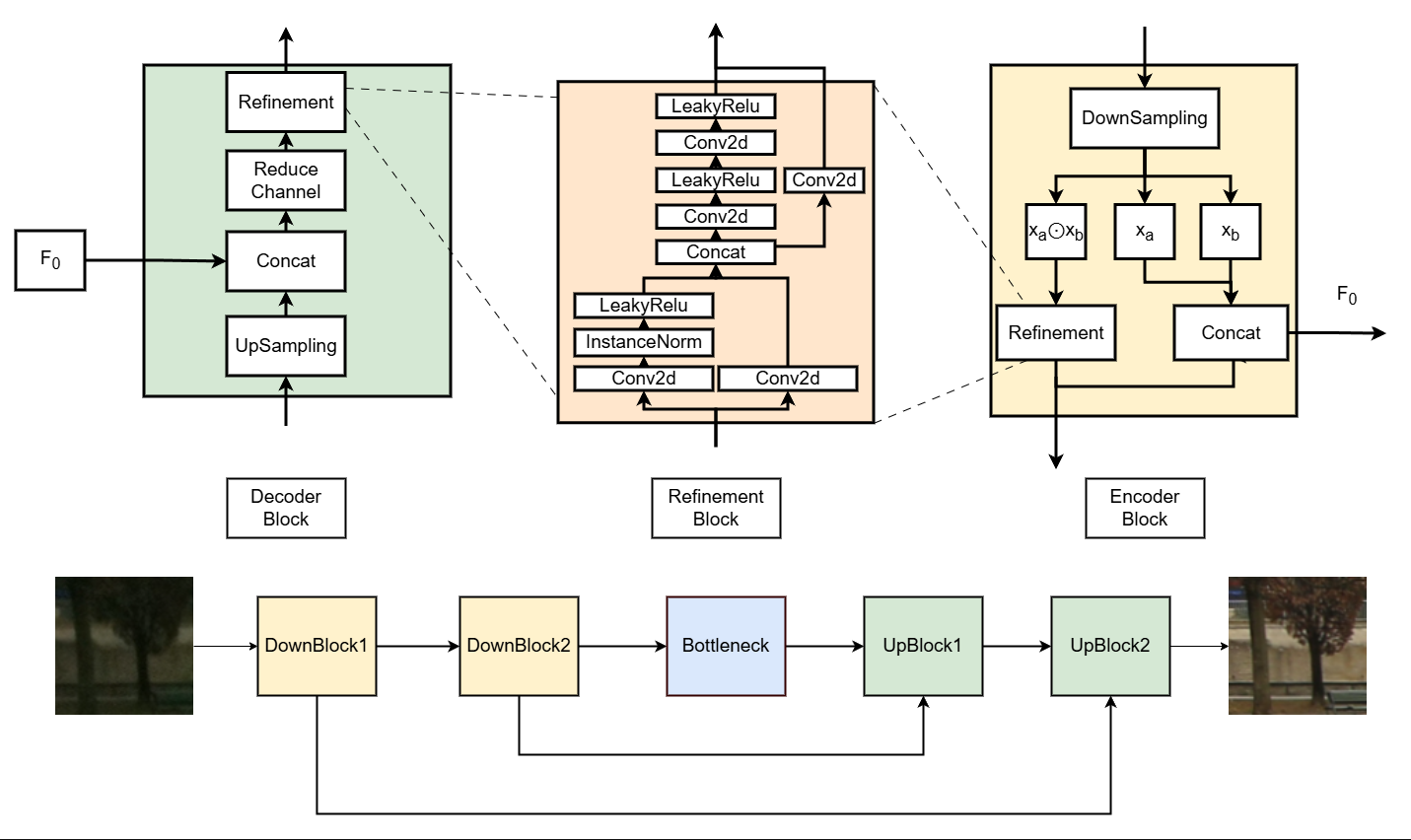
The Architecture
In order to balance global context aggregation with fine-grained texture preservation, we designed a lightweight three-scale hierarchical network
Instead of standard convolutions, we utilize a Gated Encoder Block. Each down-sampling stage uses a dual-branch architecture, producing two feature maps that are combined via an element-wise gating mechanism (a Hadamard product). This acts as a lightweight spatial-channel attention mechanism. We then preserve this entire feature triplet and forward it to the decoder via multichannel skip connections, ensuring raw directional features are not lost.
Furthermore, we apply Multi-Scale Refinement throughout the encoder and decoder. By inserting UNet-style residual convolutional blocks at multiple resolutions, the model can captures coarse illumination patterns and fine-grained local structures.
Bridging the Training-Deployment Gap
In order to ensure our model is hardware-friendly without sacrificing quality, we integrate Quantization-Aware Training (QAT) as the final optimization stage.
Mechanically, we introduce "FakeQuant" nodes into the computational graph. During the forward pass, these nodes temporarily map weights and activations to discrete levels, simulating the rounding and clamping errors of an 8-bit hardware environment. Using a Straight-Through Estimator (STE) to bypass non-differentiable rounding during the backward pass, the network proactively learns to compensate for precision loss.
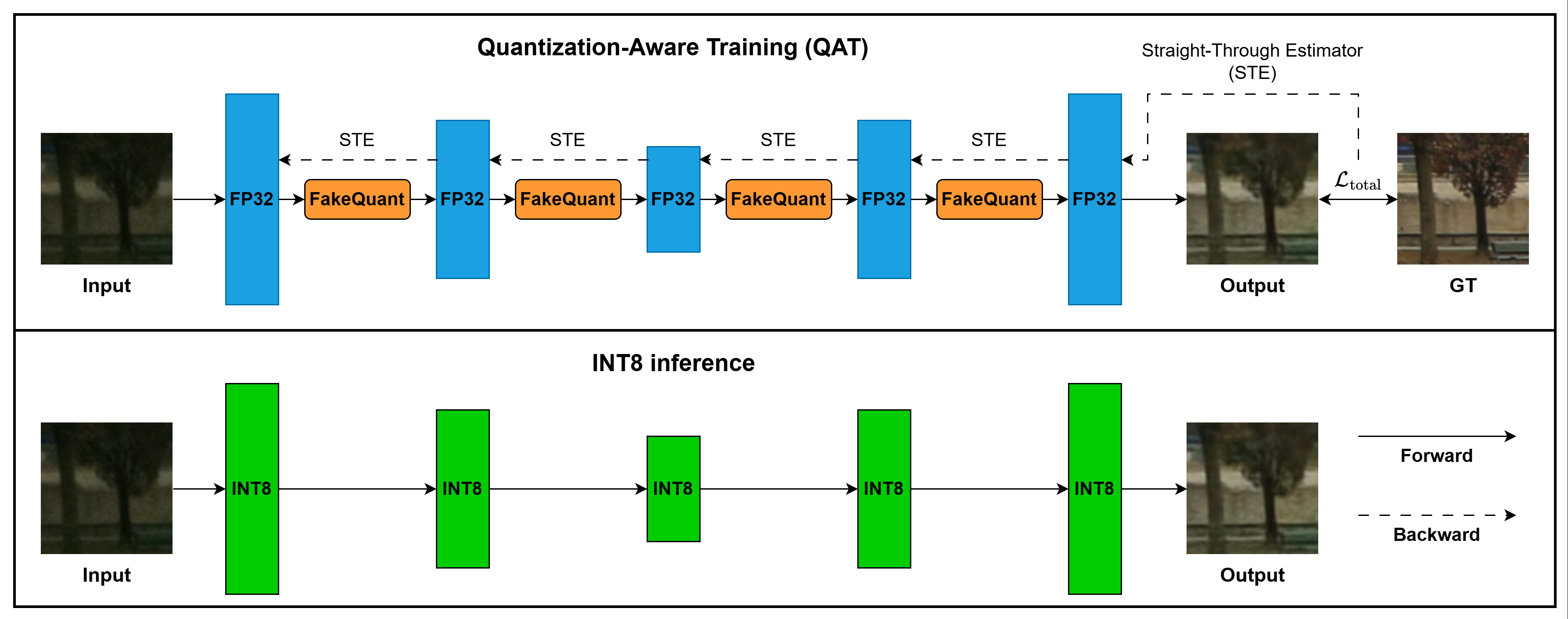
When finally converted to INT8, the performance gap between PTQ and QAT is distinct.
- Standard PTQ (INT8) yields 20.576 PSNR and 0.6139 SSIM.
- Our QAT model (INT8) achieves 21.050 PSNR and 0.725 SSIM.
By simulating quantization during training, our model recovers a massive 0.474 dB in PSNR and 0.111 in SSIM compared to the baseline PTQ. Furthermore, deploying the INT8 QAT model on a Qualcomm Neural Network Hexagon Tensor Processor (QNN HTP) reduces inference latency by approximately 72% compared to the FP16 baseline, dropping from 151 ms to just 41.8 ms.

BibTeX
@InProceedings{Thanh_2026_CVPR,
author = {Thanh, Dat To and Trong, Nghia Nguyen and Vo, Hoang and Bui-Minh, Hieu and Nguyen-Nhu, Tinh-Anh},
title = {Bridging the Training-Deployment Gap: Gated Encoding and Multi-Scale Refinement for Efficient Quantization-Aware Image Enhancement},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2026},
pages = {3847-3856}
}