STER-VLM: Spatio-Temporal With Enhanced Reference Vision-Language Models
ICCVW 2025
Abstract
We fine-tune a vision-language model for traffic video captioning and question answering by separating spatial and temporal reasoning, then filtering frames to better capture the most relevant context in each scenario.
Method
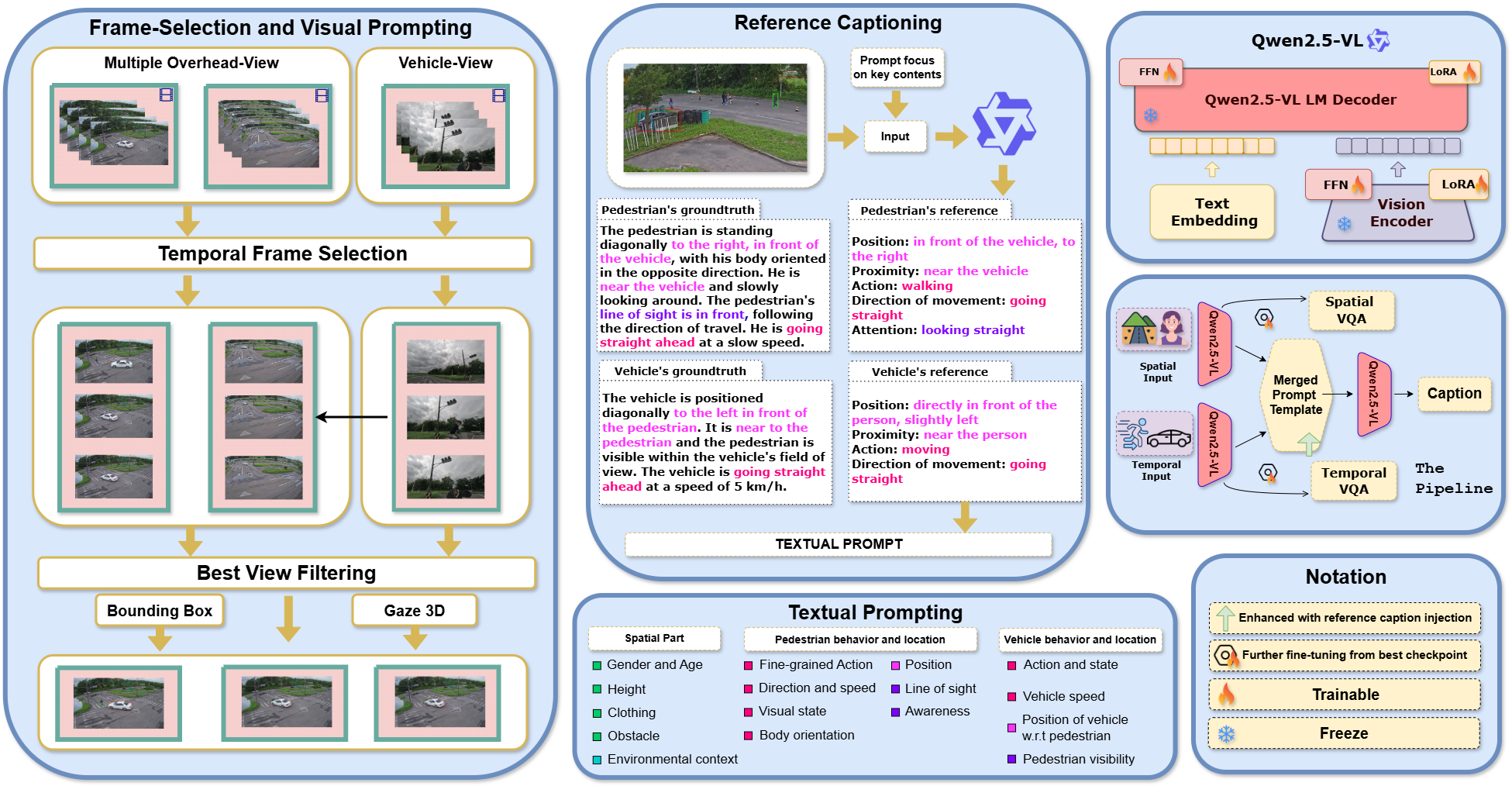
STER-VLM is built around a simple idea: separate what stays stable in a traffic scene from what changes over time. The model uses a caption decomposition strategy to split scene descriptions into spatial and temporal parts, which reduces unnecessary complexity when reasoning over long traffic videos.
The pipeline also introduces a frame selection strategy with best-view filtering so the model only receives frames that are likely to carry useful context. That makes the temporal stream more focused and reduces noise from redundant views.
Datasets
The project uses the WTS dataset and the BDD-PC-5K subset from BDD100K. Both datasets contain multi-view traffic videos, captions, and question-answer annotations. The WTS set includes 249 scenarios, while the BDD-derived portion contains thousands of dashboard videos.
Training and Validation
The full paper evaluates captioning and question-answering quality across the challenge split, together with ablation studies that compare decomposition strategies and frame-selection choices. The blog notes that the method is designed to improve both scene understanding and reasoning efficiency.
Analysis
The key strength of the approach is that it reduces the amount of redundant visual context while keeping the information that matters for traffic understanding. That makes the model better suited to real-world scenarios where multiple views and long video sequences can otherwise become difficult to process.
Conclusion
STER-VLM is a practical traffic video understanding pipeline that combines spatio-temporal decomposition, selective frame filtering, and vision-language fine-tuning to improve captioning and VQA performance in the AI City Challenge setting.
BibTeX
@InProceedings{Nguyen-Nhu_2025_ICCV,
author = {Nguyen-Nhu, Tinh-Anh and Minh, Triet Dao Hoang and To-Thanh, Dat and Le-Gia, Phuc and Vo-Lan, Tuan and Nguyen, Tien-Huy},
title = {STER-VLM: Spatio-Temporal With Enhanced Reference Vision-Language Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month = {October},
year = {2025},
pages = {5516-5525}
}